Входная и внутренняя кодировки.
Следует подчеркнуть, что слово "кодировка" в сочетании " кодировка T1" имеет не совсем обычный смысл. Эта кодировка, вообще говоря, не совпадает с кодировкой букв во входных файлах (а для некоторых символов вообще нет кода, который им соответствует во входном файле). Как же задается соответствие между ними? Есть два принципиально разных подхода.
Первый вариант состоит в том, что в программу TeX встраивается дополнительный механизм (выходящий за рамки собственно TeX'а), который считывает таблицу соответствия между кодами и автоматически перекодирует входные символы. (Можно сказать, что TeX в узком смысле этого слова ничего не знает о входной кодировке.) Обратное перекодирование производится при выдаче log}-файлов и других текстовых файлов.
Второй вариант, не выходящий за рамки TeX'а и применяемый в пакете inputenc, состоит в том, что символы входного потока становятся "активными", то есть становятся командами, порождающими символы во внутренней кодировке. Это, конечно, противоречит всей архитектуре TeX'а, поскольку там есть специальная "категория", называемая буквами (letters), а активные символы — уже не буквы. В результате работа других пакетов может нарушиться, если они не готовы к такому повороту событий, в idx-файл попадают не буквы, а команды для них (что нарушает нормальную работу программ для обработки idx-файлов) и т.д. Зато, скажем, кодировку можно переключать "на лету" в середине текста, если это зачем-то понадобится.
Кстати, внутренняя кодировка (при использовании так называемых виртуальных шрифтов) может не совпадать и с кодировкой, используемой в шрифте (будь то PostScript- или METAFONT-шрифт). Но в tfm-файлах используется как раз внутренняя кодировка.
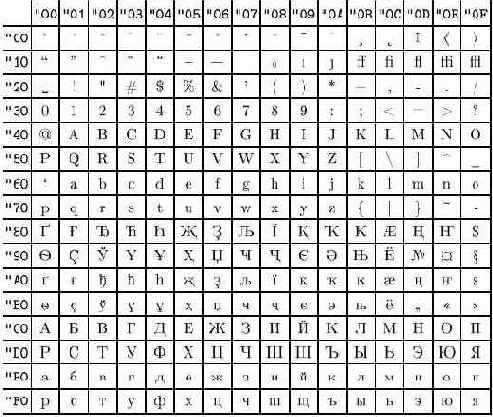
Рис. B.5. Кодировка T2A
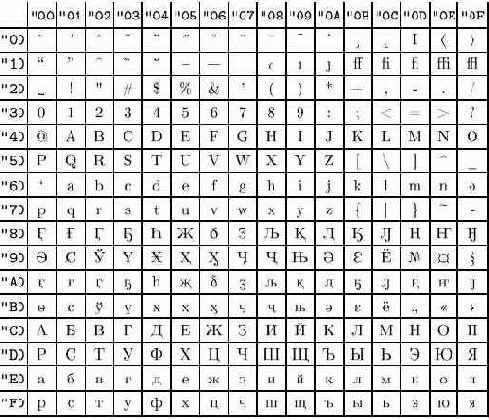
Рис. B.6. Кодировка T2В
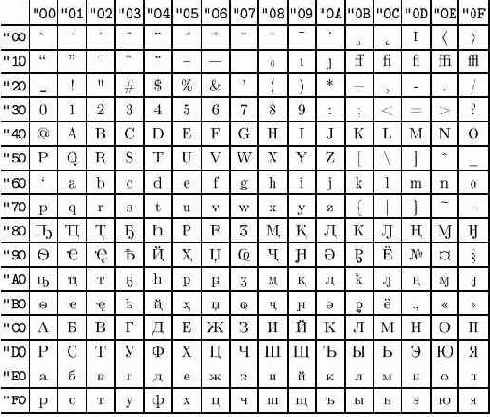
Рис. B.7. Кодировка T2C
Что же получается с русскими текстами? Для них есть несколько входных кодировок (koi8-r, cp1251, cp866) и несколько внутренних. Заметим, что при использовании одной внутренней кодировки не удается поместить в нее все кириллические символы, сохранив первую половину такой же, как в кодировке T1 (разных символов слишком много). Это было причиной появления кодировок T2A, T2B и T2C, в которых русские буквы стоят на одних и тех же местах, но вот дополнительные буквы разные. На рисунках В.5, В.6 и В.7 приведены соответствующие списки символов (набранные шрифтами LH — на сегодняшний день единственными кириллическими шрифтами, эти кодировки поддерживающими).
Представляет интерес также кодировка X2 (рис. В.8), в которой первая половина также используется для кириллических символов (в отличие от T2A, T2B и T2C, в ней присутствуют символы, необходимые для набора русских текстов в дореволюционной орфографии). Кроме этого, имеется кодировка OT2, соответствующая кодировке символов в русских шрифтах AMS, а также многие другие.
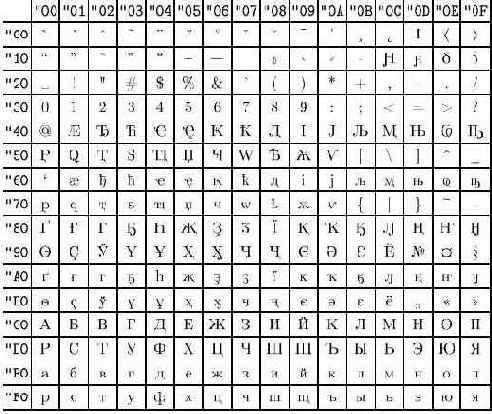
Рис. В.8. Кодировка X2